Loading... # 从汇编语言的视角来看 在函数调用的时候,需要有一条指令跳转到被调用函数的位置,这个看起来和其他控制结构没什么不同;但是在被调用函数返回的时候,我们却需要返回那条跳转过来的指令的下一条继续执行。这次用来返回的跳转究竟跳转到何处,在对应的函数调用发生之前是不知道的。比如,我们在两个不同的地方调用同一个函数,显然函数返回之后会回到不同的地址。这是一个很大的不同:其他控制流都只需要跳转到一个 *编译期固定下来* 的地址,而函数调用的返回跳转是跳转到一个 *运行时确定* (确切地说是在函数调用发生的时候)的地址。 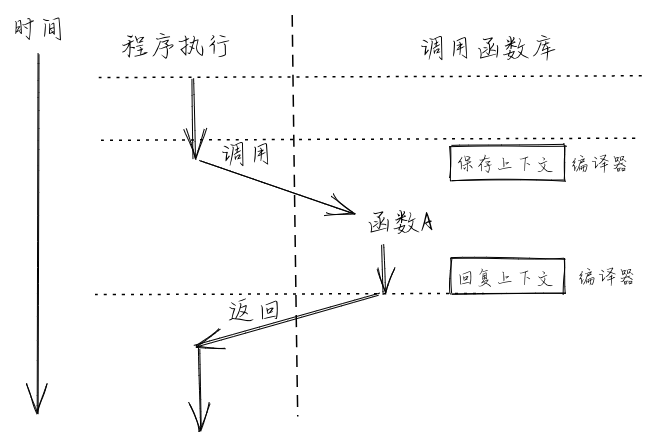 对此,指令集必须给用于函数调用的跳转指令一些额外的能力,而不只是单纯的跳转。对于8086汇编来说,有一条伪指令符合该特征,也就是 `call` 伪指令,它会使得 `sp` 寄存器 减少对应的字节数,然后将当前的 `IP` 保存到栈顶(在执行当前指令之前,`IP` 就已经指向下一条指令了),然后使得 `IP` 指向被调用的函数地址。而 `ret` 伪指令则是该过程的逆过程,即将保存在栈内的返回地址出栈放入 `IP` 内。而在 RISC-V 架构上,有两条指令即符合这样的特征: | 指令 | 指令功能 | | ---------------------------- | ------------------------------------------------ | | $jal\ rd,\ imm[20:1]$ | $rd\leftarrow pc+4$<br />$pc\leftarrow pc+imm$ | | $jalr\ rd,\ (imm[11:0])rs$ | $rd\leftarrow pc+4$<br />$pc\leftarrow rs+imm$ | <div class="tip inlineBlock info"> **RISC-V 指令各部分含义** 在大多数只与通用寄存器打交道的指令中, rs 表示 **源寄存器** (Source Register), imm 表示 **立即数** (Immediate),是一个常数,二者构成了指令的输入部分;而 rd 表示 **目标寄存器** (Destination Register),它是指令的输出部分。rs 和 rd 可以在 32 个通用寄存器 x0~x31 中选取。但是这三个部分都不是必须的,某些指令只有一种输入类型,另一些指令则没有输出部分。 </div> 从中可以看出,这两条指令在设置 pc 寄存器完成跳转功能之前,还将当前跳转指令的下一条指令地址保存在 rd 寄存器中,即 $rd\leftarrow pc+4$ 这条指令的含义。(这里假设所有指令的长度均为 4 字节)在 RISC-V 架构中,通常使用 `ra` 寄存器(即 `x1` 寄存器)作为其中的 `rd` 对应的具体寄存器,因此在函数返回的时候,只需跳转回 `ra` 所保存的地址即可。事实上在函数返回的时候我们常常使用一条 **伪指令** (Pseudo Instruction) 跳转回调用之前的位置: `ret` 。它会被汇编器翻译为 `jalr x0, 0(x1)`,含义为跳转到寄存器 `ra` 保存的物理地址,由于 `x0` 是一个恒为 `0` 的寄存器,在 `rd` 中保存这一步被省略。 总结一下,在进行函数调用的时候,我们通过 `jalr` 指令保存返回地址并实现跳转;而在函数即将返回的时候,则通过 `ret` 伪指令回到跳转之前的下一条指令继续执行。这样,RISC-V 的这两条指令就实现了函数调用流程的核心机制。 可以发现,汇编指令在实现函数调用流程的核心机制大差不差,其思想都是在调用函数前保存返回地址,在函数调用结束时,恢复到之前的地址。 在栈内保存函数地址还好办,但是像 RISC-V 架构这样,指令将地址保存在 ra 寄存器中,我们就得保证 ra 寄存器在函数调用过程中不被篡改了,单次调用还好说,但是在现实应用中,我们离不开函数 **多层嵌套调用** 的情形。我们很容易想象,如果函数不支持嵌套调用,那么编程将会变得多么复杂。如果我们试图在一个函数 f 中调用一个子函数,在跳转到子函数 g 的同时,ra 会被覆盖成这条跳转指令的下一条的地址,而 ra 之前所保存的函数 f 的返回地址将会 *永久丢失* 。 因此,若想正确实现嵌套函数调用的控制流,我们必须通过某种方式保证:在一个函数调用子函数的前后,`ra` 寄存器的值不能发生变化。但实际上,这并不仅仅局限于 `ra` 一个寄存器,而是作用于所有的通用寄存器。这是因为,编译器是独立编译每个函数的,因此一个函数并不能知道它所调用的子函数修改了哪些寄存器。而站在一个函数的视角,在调用子函数的过程中某些寄存器的值被覆盖的确会对它接下来的执行产生影响。因此这是必要的。我们将由于函数调用,在控制流转移前后需要保持不变的寄存器集合称之为 **函数调用上下文** (Function Call Context) 。 由于每个 CPU 只有一套寄存器,我们若想在子函数调用前后保持函数调用上下文不变,就需要物理内存的帮助。确切的说,在调用子函数之前,我们需要在物理内存中的一个区域 **保存** (Save) 函数调用上下文中的寄存器;而在函数执行完毕后,我们会从内存中同样的区域读取并 **恢复** (Restore) 函数调用上下文中的寄存器。实际上,这一工作是由子函数的调用者和被调用者(也就是子函数自身)合作完成。函数调用上下文中的寄存器被分为如下两类: * **被调用者保存(Callee-Saved) 寄存器** :被调用的函数可能会覆盖这些寄存器,需要被调用的函数来保存的寄存器,即由被调用的函数来保证在调用前后,这些寄存器保持不变; * **调用者保存(Caller-Saved) 寄存器** :被调用的函数可能会覆盖这些寄存器,需要发起调用的函数来保存的寄存器,即由发起调用的函数来保证在调用前后,这些寄存器保持不变。 从名字中可以看出,函数调用上下文由调用者和被调用者分别保存,其具体过程分别如下: * 调用函数:首先保存不希望在函数调用过程中发生变化的 **调用者保存寄存器** ,然后通过 jal/jalr 指令调用子函数,返回之后恢复这些寄存器。 * 被调用函数:在被调用函数的起始,先保存函数执行过程中被用到的 **被调用者保存寄存器** ,然后执行函数,最后在函数退出之前恢复这些寄存器。 我们发现无论是调用函数还是被调用函数,都会因调用行为而需要两段匹配的保存和恢复寄存器的汇编代码,可以分别将其称为 **开场** (Prologue) 和 **结尾** (Epilogue),它们会由编译器帮我们自动插入,来完成相关寄存器的保存与恢复。一个函数既有可能作为调用者调用其他函数,也有可能作为被调用者被其他函数调用。 <div class="tip inlineBlock info"> **寄存器保存与编译器优化** 这里值得说明的是,调用者和被调用者实际上只需分别按需保存调用者保存寄存器和被调用者保存寄存器的一个子集。对于调用函数而言,在调用子函数的时候,即使子函数修改了调用者保存寄存器,编译器在调用函数中插入的代码会恢复这些寄存器;而对于被调用函数而言,在其执行过程中没有使用到的被调用者保存寄存器也无需保存。编译器在进行后端代码生成时,知道在这两个场景中分别有哪些值得保存的寄存器。从这一角度也可以理解为何要将函数调用上下文分成两类:可以让编译器尽可能早地优化掉一些无用的寄存器保存与恢复操作,提高程序的执行性能。 </div> ## 调用规范 **调用规范** (Calling Convention) 约定在某个指令集架构上,某种编程语言的函数调用如何实现。它包括了以下内容: 1. 函数的输入参数和返回值如何传递; 2. 函数调用上下文中调用者/被调用者保存寄存器的划分; 3. 其他的在函数调用流程中对于寄存器的使用方法。 调用规范是对于一种确定的编程语言来说的,因为一般意义上的函数调用只会在编程语言的内部进行。当一种语言想要调用用另一门编程语言编写的函数接口时,编译器就需要同时清楚两门语言的调用规范,并对寄存器的使用做出调整。 <div class="tip inlineBlock info"> **RISC-V 架构上的 C 语言调用规范** RISC-V 架构上的 C 语言调用规范可以在 [这里](https://riscv.org/wp-content/uploads/2015/01/riscv-calling.pdf) 找到。 它对通用寄存器的使用做出了如下约定: | 寄存器组 | 保存者 | 功能 | | --------------------------- | -------------- | ---------------------------------------------------------- | | a0~a7(`x10~x17` ) | 调用者保存 | 用来传递输入参数。其中的 a0 和 a1 还用来保存返回值。 | | t0~t6(`x5~x7,x28~x31` ) | 调用者保存 | 作为临时寄存器使用,在被调函数中可以随意使用无需保存。 | | s0~s11(`x8~x9,x18~x27` ) | 被调用者保存 | 作为临时寄存器使用,被调函数保存后才能在被调函数中使用。 | 剩下的 5 个通用寄存器情况如下: * zero( `x0` ) 之前提到过,它恒为零,函数调用不会对它产生影响; * ra( `x1` ) 是调用者保存的,不过它并不会在每次调用子函数的时候都保存一次,而是在函数的开头和结尾保存/恢复即可。虽然 `ra` 看上去和其它被调用者保存寄存器保存的位置一样,但是它确实是调用者保存的。 * sp( `x2` ) 是被调用者保存的。这个是之后就会提到的栈指针 (Stack Pointer) 寄存器。 * fp( `s0` ),它既可作为s0临时寄存器,也可作为栈帧指针(Frame Pointer)寄存器,表示当前栈帧的起始位置,是一个被调用者保存寄存器。 </div> 其实光看上面的介绍,就应该知道,其实在 RISC-V 指令集中,对于函数调用上下文的保存也是需要利用到栈的,不过这里再补充几个关键点的解释。`sp` 寄存器常用来保存 **栈指针** (Stack Pointer),它指向内存中栈顶地址。在 RISC-V 架构中,栈是从高地址向低地址增长的。在一个函数中,作为起始的开场代码负责分配一块新的栈空间,即将 `sp` 的值减小相应的字节数即可,于是物理地址区间 $[新sp,旧sp)$ 对应的物理内存的一部分便可以被这个函数用来进行函数调用上下文的保存/恢复,这块物理内存被称为这个函数的 **栈帧** (Stack frame)。同理,函数中的结尾代码负责将开场代码分配的栈帧回收,这也仅仅需要将 `sp` 的值增加相同的字节数回到分配之前的状态。这也可以解释为什么 `sp` 是一个被调用者保存寄存器。 <div class="tip inlineBlock info"> **栈帧 stack frame** 我们知道程序在执行函数调用时,调用函数和被调用函数使用的是同一个栈。在通常的情况下,我们并不需要区分调用函数函数和被调用函数分别使用了栈的哪个部分。但是,当我们需要在执行过程中对函数调用进行调试或backtrace的时候,这一信息就很重要了。简单的说,栈帧(stack frame)就是一个函数所使用的栈的一部分区域,所有函数的的栈帧串起来就组成了一个完整的栈。一般而言,当前执行函数的栈帧的两个边界分别由栈指针 (Stack Pointer)寄存器和栈帧指针(frame pointer)寄存器来限定。 </div> 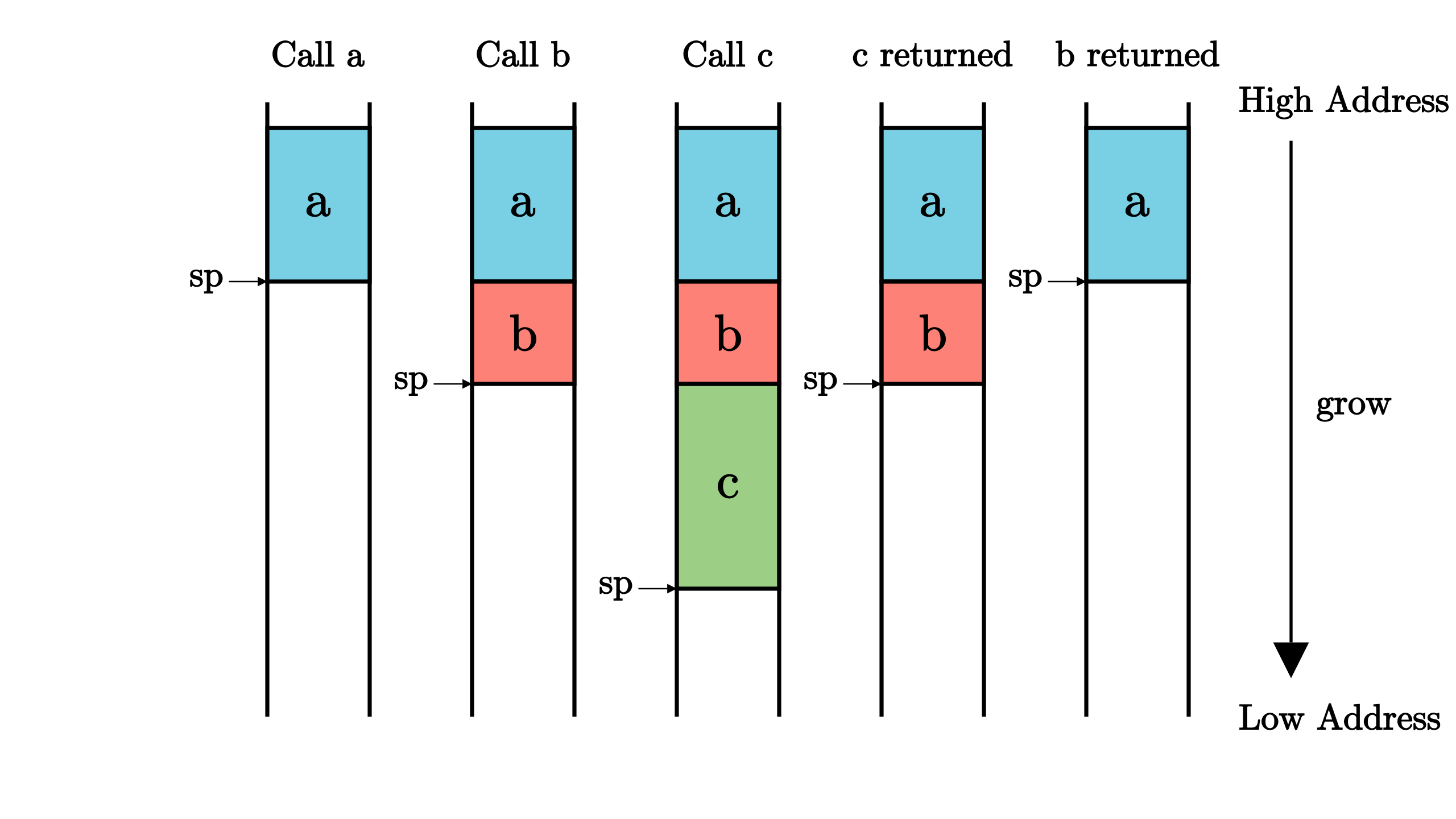 在合适的编译选项设置之下,一个函数的栈帧内容可能如下图所示: 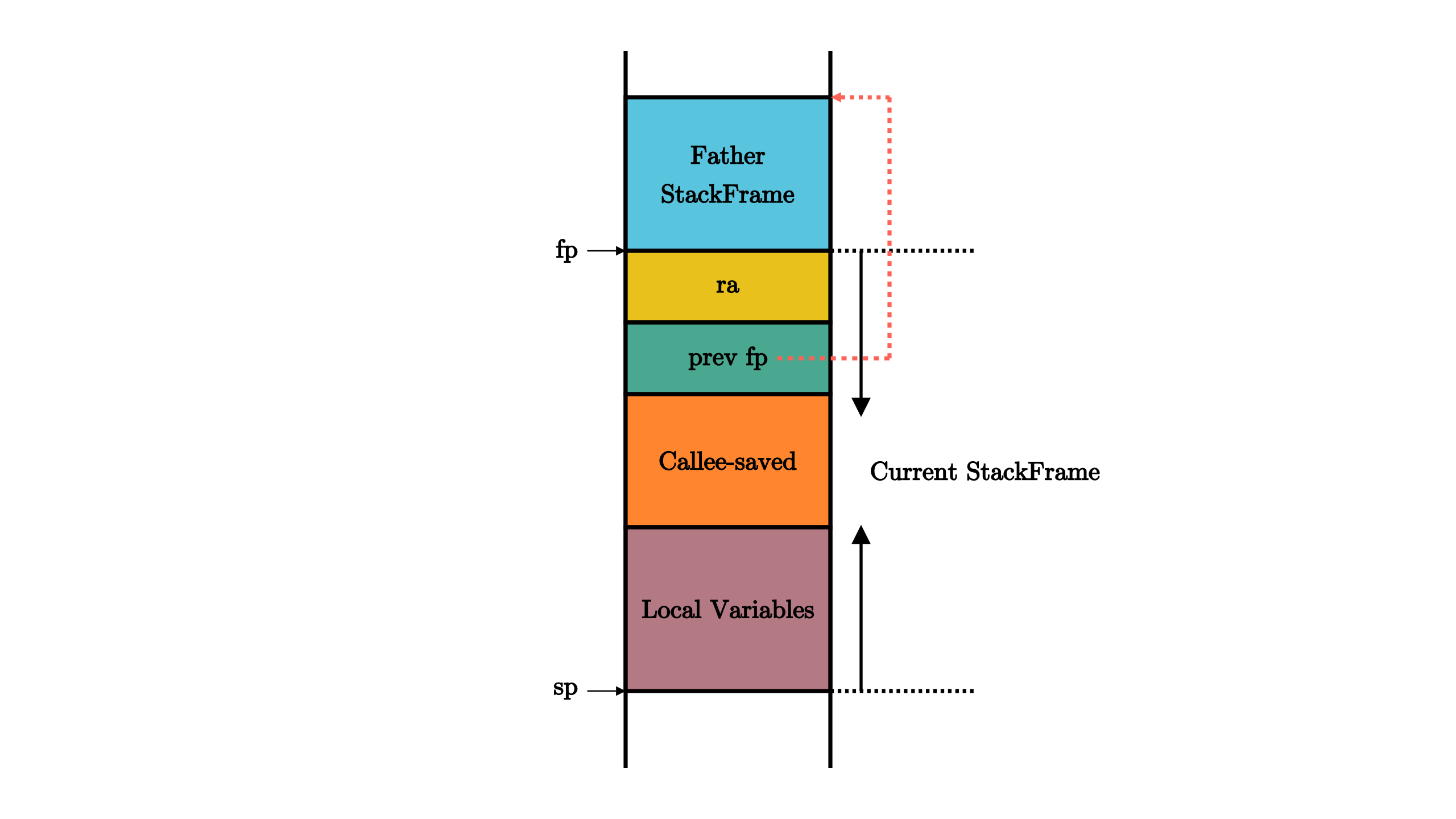 它的开头和结尾分别在 sp(x2) 和 fp(s0) 所指向的地址。按照地址从高到低分别有以下内容,它们都是通过 `sp` 加上一个偏移量来访问的: * `ra` 寄存器保存其返回之后的跳转地址,是一个调用者保存寄存器; * 父亲栈帧的结束地址 `fp` ,是一个被调用者保存寄存器; * 其他被调用者保存寄存器 `s1` ~ `s11` ; * 函数所使用到的局部变量。 因此,栈上多个 `fp` 信息实际上保存了一条完整的函数调用链,通过适当的方式我们可以实现对函数调用关系的跟踪。 至此,就基本上说明了函数调用是如何基于栈来实现的。 Last modification:April 8, 2022 © Allow specification reprint Support Appreciate the author AliPayWeChat Like 2 如果觉得我的文章对你有用,请随意赞赏

